
"If the agent is 85% accurate, it means there is a 15% chance someone will be upset using the product. So if it's 100%, I can sleep better."
- Akar Sumset, Co-Founder and CPO, Neol
Case study in brief
Neol runs the network intelligence layer for governments and institutions that make high-stakes decisions about people and relationships, a setting where an agent that is "usually right" is a product failure: results surface real people and must be defensible after the fact. Neol's agents originally ran on page-long natural-language prompts that were brittle and, more seriously, not reproducible, since the same input produced different reasoning traces on different runs. Neol rebuilt the stack on SERV Reasoning, OpenServ's structured reasoning engine, in which a high-capacity model generates the logic once as a bounded reasoning graph and a smaller model executes that graph node by node, with no room to drift.
On a representative agent that extracts years of experience from a CV, measured across 2,400 runs against an identical evaluation suite, overall reliability rose:
Previous production stack, prompt-engineered: 54.1%
Research-paper findings applied directly: 63.1%
Full SERV Reasoning methodology: 100% across every category
The same architecture produces the property that made the system deployable under regulatory scrutiny: every result traces to an inspectable decision graph that applies the same logic every time, with a specific node to challenge if a client contests it. As Akar Sumset, Neol's co-founder, puts it, "the auditability matters as much as the accuracy."
Before SERV Reasoning | After SERV Reasoning |
|---|---|
54.1% reliability across 2,400 runs | 100% reliability across 2,400 runs |
Unpredictable reasoning traces | Deterministic decision graphs |
Prompt archaeology and hope | Auditable by design |
The pattern is not specific to Neol. Wherever reliability, reproducibility, cost, and explainability matter, which is most enterprise and public-sector work, prompt engineering scales until it does not, and the move to bounded, inspectable reasoning is what carries an agent the rest of the way. The full case study, with the production findings and the per-category evaluation, follows.
Source: Neol internal evaluation system, 22 April 2026. Research: Amcalar and Cinar (2025), arXiv:2512.15959.
The workload
Neol operates the network intelligence layer for organisations whose most valuable asset is their relationships. Its customers include governments, public institutions, international bodies, large mission-driven organisations, and strategic corporates working on long-term agendas in employment, climate, innovation, and economic diversification. The product converts the messy reality of an organisation's connections (emails, call notes, proposals, CRM records, web data, and the knowledge people carry in their heads) into an ecosystem view that supports decision-making.
When an official asks who in the network has run a climate programme in the Gulf and who can make the introduction, the system has to return the right person, supported by reasoning the client can inspect. In that setting, "usually right" is a product failure: the answer has to be correct, consistently, and it has to be verifiable.
The structural problem Neol addresses is well documented. By the industry analyses Neol cites, 80 to 90 percent of enterprise data is unstructured and two-thirds of it goes unused; knowledge workers spend roughly 1.8 hours each day looking for information that already exists somewhere in their own systems; and B2B contact records decay by as much as 70 percent per year. Organisations hold more relationship data than ever and are less able to use it. Neol sells the layer that closes that gap, for customers whose decisions about who to place in a room, invite into a programme, or bring into a partnership carry real consequences and must be defensible after the fact. That last requirement, defensibility, is what shaped the rebuild described here.
A reliability problem and a reproducibility problem
Neol's agents ran on natural-language prompts that, for a single agent, sometimes stretched to pages. The behaviour was brittle. Small, word-level edits produced unpredictable shifts in output, and fixing one edge case tended to break another that had previously worked. The engineering team had no principled way to tell whether a given change was an improvement or simply a different failure mode.
Beneath the brittleness sat a deeper problem: repeatability. As Akar Sumset, Neol's co-founder, describes the pre-integration state: "The same input could produce meaningfully different reasoning traces on different runs. We had no principled way to know whether an iteration was actually an improvement or just trading one failure mode for another." In a consumer product that variance is a nuisance; in this context it is a product failure. When a government user asks why a particular person appeared in a result, "the model just decided to" is not a defensible answer, and neither is "the model usually decides that." A reasoning process that produces different traces on different runs cannot be audited, improved systematically, or deployed where its decisions will be questioned.
Sumset frames what the constraint meant for product fit: "Our product surfaces real people to government clients and strategic institutions making high-stakes decisions. A reasoning process that 'usually works' isn't fit for that context. What we needed was reasoning we could inspect, test, and improve systematically rather than nudge through prompt archaeology and hope."
In Neol's words, the gap was as much about the medium as the model: "There is not much reasoning best practices. We need a more unified, more transparent reasoning rather than just text, because text is not as transparent and as understandable as flow."
What SERV Reasoning is
SERV Reasoning is OpenServ's structured reasoning engine. At its base layer, instead of asking a model to think step by step in open prose, it binds the model to execute a custom reasoning graph expressed in a machine-native format, Mermaid flowchart syntax.
The primary mechanism separates the work into two phases. A high-capacity model generates the reasoning graph, laying out branches, validation checkpoints, and decision nodes as an explicit plan; next, smaller models execute the bounded graphs at inference time, node by node, following the plan.
Two properties follow. Because the execution model is bound to a fixed plan, it cannot drift; there is nowhere to drift to. And because the expensive design step runs once while execution runs thousands of times, the economics change: the frontier-scale rate is paid for the architecture of the reasoning, not for every query that uses it. Agent builders integrate it through the SERV API with a one-line change.
The research underpinning SERV Reasoning (Amcalar and Cinar, 2025, arXiv:2512.15959) validates the core result across several benchmarks, including GSM-Hard, SCALE MultiChallenge, and AdvancedIF: well-formed bounded reasoning graphs lift smaller models into territory previously reserved for frontier-scale systems, at a fraction of the cost.
The bounded reasoning graph is the core of the engine, and the layer on which Neol's stack relies. The engine comprises several further layers built for production and enterprise deployment:
Verification by shadow agents that independently re-check the primary reasoning, with a verification-hints feature that focuses each check on the steps most likely to fail.
PromptGuard, a dedicated defence against prompt-injection and related attacks.
Privacy and data-protection tooling, including trusted execution environments (TEEs) with end-to-end encryption for large enterprises, and data residency in the EU and the United States.
Graph sharding that preserves deterministic outputs as workloads scale.
An audit layer that gives insight into the agent's decisions and makes the reasoning itself auditable, examined shard by shard across the graph.
Support for open-source models run under SERV Reasoning.
API integrations with enterprise gateways.
This case study demonstrates the bounded-graph core in production. The surrounding layers are what allow the same engine to meet the security, privacy, residency, and scale requirements of larger regulated deployments without altering the reasoning model underneath. The production results that follow extend the picture in ways the paper does not.
Two findings from production
When Neol moved its agent flows onto SERV Reasoning, two patterns emerged that the paper did not describe. Neol began with its largest and most consequential agents: the filter-criteria generator, the keyword synthesiser, and the candidate-reasoning pipeline.
The first finding is that large graphs fail and need to be decomposed early. Even a well-structured graph can be too large; past a certain complexity threshold, the execution model begins to lose the thread. This led OpenServ to add a layer that breaks each agent task into smaller, tightly scoped sub-graphs, each handling one discrete reasoning task with its own explicit steps and verification points. Accuracy rose substantially. Finding the right balance between graph size and complexity was a significant undertaking in its own right, resolved through testing against live workloads.
The second finding is that binary judgments outperform free-form reasoning wherever they can be applied. Framing a decision point as a binary yes/no judgment outperforms open-ended reasoning at the node level when the scale is tuned correctly, though not every step should be reduced to a binary. Sumset describes this as "not documented in the original research paper, but something that came directly from our production experience." Both findings came from running the engine against real workloads, and together they produced a reasoning surface that is, in his words, "deterministic enough to be testable."
The experience-extraction agent
Neol's search product lets clients filter candidates by experience: mentors with fewer than six years, speakers with at least ten years in fintech, and so on. To support this, Neol runs a small, purpose-built agent that reads a candidate's CV and extracts years of experience across several categories: minimum, maximum, and exact figures, expressed both in numerals and in words.
The task looks trivial and is not. As Miguel Gonzalez Wanzek, Neol's lead engineer, puts it: "It's a very simple agent, but if you don't get this right, the search falters tremendously."
The difficulty is structural rather than superficial. The agent has to do two dependent things well: read the document correctly, and then decide, on the basis of that reading, when to invoke its tools. A candidate's tenure may be stated as a range, as an exact figure, or in words rather than numerals, and the correct extraction is what determines whether the right tool fires at the right moment. When the two steps are collapsed into a single free-form prompt, an unreliable extraction propagates directly into an unreliable decision, and the downstream search degrades.
Neol evaluated three implementations of the same agent against the same evaluation suite of 24 scenarios, each run 100 times, for 2,400 runs per implementation.
Implementation | Overall reliability |
|---|---|
1. GPT-5.4-nano, prompt-engineered | 54.1% |
2. Research-paper findings applied directly | 63.1% |
3. Full SERV Reasoning methodology | 100% (all five categories) |
Source: Neol internal evaluation system, 22 April 2026; identical evaluation suite across all three implementations. Per-category reliability reports for each implementation are included as exhibits.

In the first implementation, a prompt-engineered GPT-5.4-nano, overall reliability measured 54.1 percent. The correct tool fired at roughly the right moment 50 to 60 percent of the time, and for the remainder it was either not called when it should have been or called incorrectly, an unreliable extraction surfacing as an unreliable decision. Reliability was also uneven across the extraction categories, ranging from one category that produced no reliable answers at all to another that was very nearly complete.
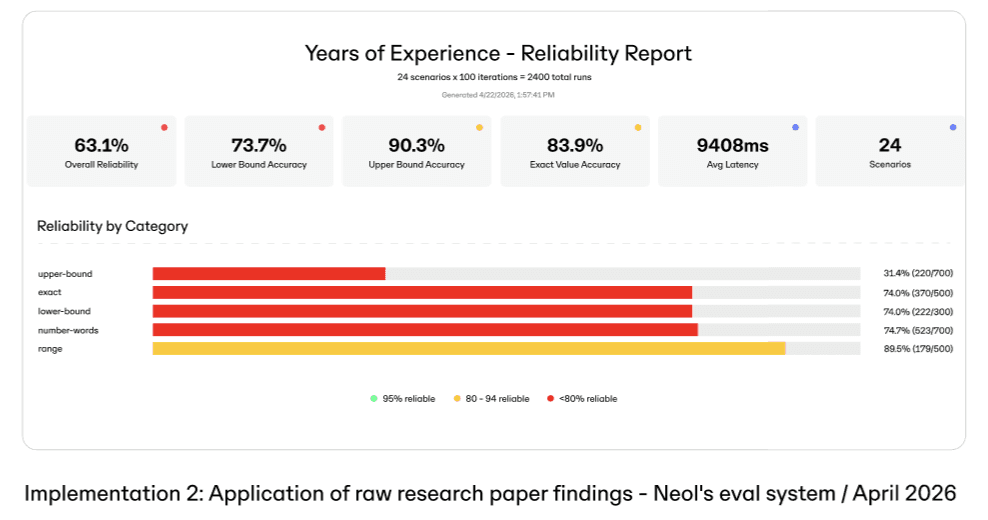
The second implementation applied the findings of the research paper directly. Overall reliability rose to 63.1 percent, a clear improvement but still short of what the workload required.
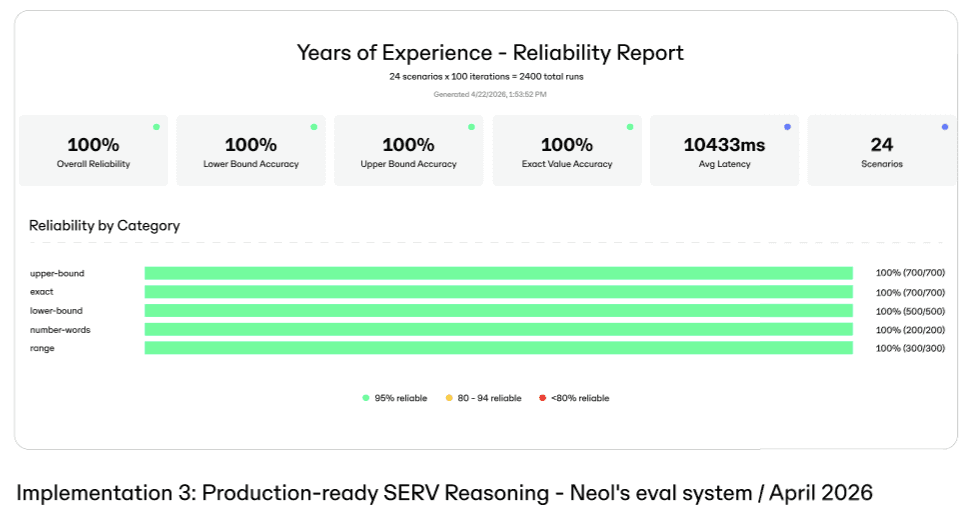
The third implementation applied the full SERV Reasoning methodology, combining structured reasoning graphs, sub-graph decomposition, and binary-judgment framing. Decomposition isolated the extraction sub-tasks behind their own verification points so that a reading error could be caught rather than carried forward, and binary framing converted the gating decisions into judgments the evaluation suite could test directly. That combination eliminated failure on the task: reliability reached 100 percent, uniformly across all five categories, over the same 2,400 runs.
The progression from 54.1 percent to 100 percent is the substantive result of this case study, and it clarifies what the published benchmarks measure. They describe a floor, not a ceiling. With production experience and domain-specific optimisation, the methodology exceeds the paper's figures, here reaching 100 percent.
The key bottleneck: cost
A reliability gain that arrives at ten times the cost is, in most enterprise settings, a non-starter; a reasoning process that spends tokens on unbounded chain-of-thought is expensive at thousands of queries and prohibitive at millions. SERV Reasoning avoids that trade-off by construction. The frontier-scale cost is incurred once, when the graph is designed, while the recurring execution runs on a smaller model. Reliability and cost are therefore both satisfied before the discussion reaches the property that, for Neol's customers, proved decisive.
Accountability
For Neol's customers, reliability and cost are necessary but not sufficient; the property that changed how Neol sells into government is accountability. When a client asks why a particular candidate appeared in a search, which is to say why this person, why now, and why ahead of the hundred others who nearly matched, Neol can point to the exact reasoning structure that produced the result: a traceable, inspectable decision graph that applies the same logic every time. If the client wishes to contest the result, there is a specific node to contest. In environments where AI systems are treated with regulatory caution and where a hallucinated output can carry policy consequences, this is not a convenience; it is what makes the system deployable in the first place. As Sumset puts it: "For companies working in high-stakes domains, the auditability matters as much as the accuracy. When a client asks why a particular result appeared, you can point to the reasoning structure rather than shrugging at a black-box prompt. That's a qualitatively different relationship with the technology."
The auditability advantage compounds with the reliability advantage. A fully reliable system that cannot be inspected is a black box that happens to be accurate; a fully reliable system that exposes its reasoning is a usable instrument for a regulator, a user, or an auditor. Neol now has both.
The Audit loop
Alongside the reasoning rebuild, Neol now operates an in-house evaluation platform that scores every version of every reasoning graph and returns numerical comparisons. That platform is the seed of the SERV Reasoning Audit tool, scheduled for integration with the Public API in Phase 2.4 of the roadmap. The question "is this change good?" was previously a matter of judgement, checked by hand and accompanied by the hope that nothing else had quietly broken; it is now a number, with each structural change producing an evaluation delta. Sumset describes the shift: "We finally have a feedback loop we could trust. Before, improving one thing meant manually checking whether other things had broken. Now we can make a targeted structural change to a reasoning graph, run it through evals, and get a signal that tells us whether we moved forward or backward. That closed loop transformed how fast we could iterate."
This is the part of adopting structured reasoning that is least discussed. A structured architecture makes the reasoning inspectable; inspectable reasoning makes evaluation traceable; traceable evaluation turns iteration from hope into engineering. The dependency runs in one direction: without the loop, neither sub-graph decomposition nor binary-judgment framing would have surfaced, because both depended on being able to measure whether a change helped. A team running agents in production without a tight evaluation loop is operating without that feedback, and structured reasoning is what makes the loop meaningful.
What generalises beyond Neol
Neol's experience generalises to any setting where reliability, reproducibility, cost efficiency, and explainability matter, which is to say most enterprise and public-sector work. Iterating on long-form system prompts eventually meets the barrier Neol met. Prompt engineering scales until it does not, and when it stops scaling the failure is not that the agent is slow; it is that the agent is unreliable in ways the team cannot diagnose, cannot reproduce, and cannot explain to a customer.
SERV Reasoning reframes the problem as an architectural one: reasoning becomes something that can be versioned, tested, decomposed, and improved like code. The gains Neol realised, from 54.1 percent reliability to 100 percent and from unpredictable traces to deterministic decision graphs, are available to any team willing to decompose its agents the same way.
About this case study
Neol is a network intelligence company working with governments, public institutions, and strategic organisations on high-stakes matching and decision-support. SERV Reasoning, developed by OpenServ with Neol as design partner, is the structured-reasoning framework, based on the BRAID architecture, that powers Neol's agent stack. Quotations are from Akar Sumset (Co-Founder and CPO, Neol) and Miguel Gonzalez Wanzek (Lead Engineer, Neol), used with permission. The underpinning research is published as Amcalar, A. and Cinar, E. (2025). BRAID: Bounded Reasoning for Autonomous Inference and Decisions. arXiv:2512.15959.
Footnotes:
1. OpenServ achieves state-of-the-art performance on SWE-bench Verified, which evaluates AI models’ ability to solve real-world software issues. See the appendix for more information on scaffolding.
2. OpenServ AI understands customer history1 and context to offer tailored responses.
3. OpenServ achieves state-of-the-art performance on SWE-bench Verified, which evaluates AI models’ ability to solve real-world software issues. See the appendix for more information on scaffolding.
🍔 Our Publications
Announcement
10 Quick Takeaways on Multi-Agent Systems & Autonomous AI
Tech Insight
The Missing Piece in AI Reasoning
Announcement
Introducing Browser Use: A Productivity Unlock for OpenServ Agent Teams
Tech Insight
Introducing Shadow Agents: The Invisible Game-Changer in Agentic Collaboration
Tech Insight